Smart Surveillance Application
This example is depicted in Figure 1: Anatomy and was provided by Pedro Silva. The example consists of data producers at the Edge (8 nodes, each one with 40 cameras); gateways at the Fog (4 nodes, each one with a java application to process images); and a Flink Cluster (1 node) and a Kafka Cluster (1 node) at the Cloud. The Flink Cluster is composed of one Job Manager and one Task Manager. The Kafka Cluster consists of a Zookeeper server and a Kafka Broker. Lastly, in a single node we have the metrics collector, an java application to collect metrics such as the end-to-end latency.
In this example you will learn how to:
Configure a Flink Cluster and a Kafka Cluster.
Deploy 4 gateways and 320 data producers and interconnect them in round-robin.
Define network constraints (delay, loss, and bandwidth) between the Edge, Fog, and Cloud infrastructures.
Manage and run Flink Job, Kafka broker, gateways, and data producers.
Check end-to-end execution.
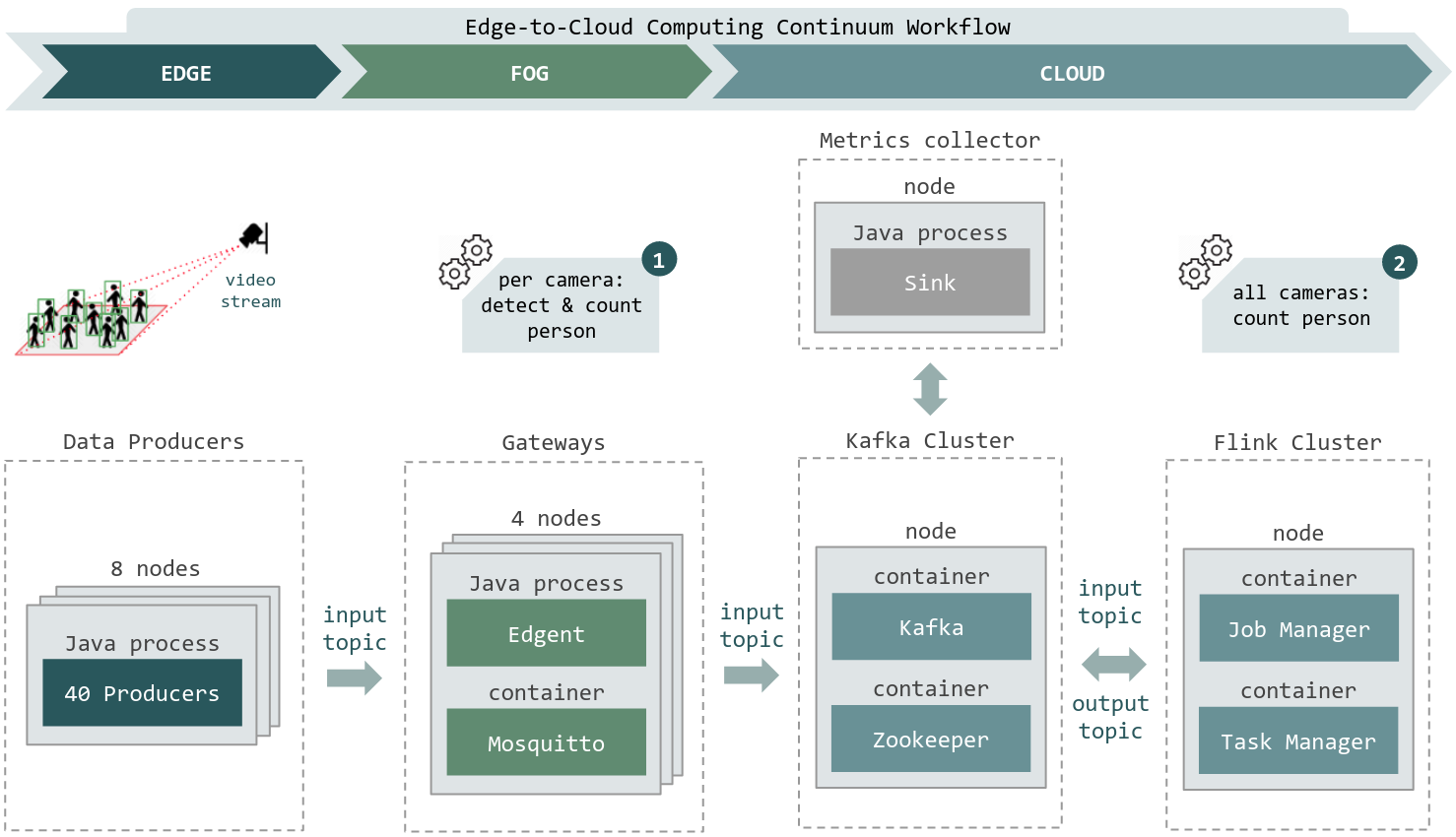
Figure 1: Anatomy
Experiment Artifacts
Following the instructions below you can get access to the experiments artifacts required to run this application. These artifacts refers to applications, libraries, dataset, and configuration files.
# G5K frontend
$ ssh rennes.grid5000.fr
$ tmux
$ cd git/
$ git clone https://gitlab.inria.fr/E2Clab/examples/cctv
$ cd cctv/
$ ls
artifacts/ # contains dataset/, libs/, libs-opencv/, and Flink job
cluster-2020/ # contains the code used to generate the charts
getting_started/ # contains layers_services.yaml, network.yaml, and workflow.yaml
Defining the Experimental Environment
Layers & Services Configuration
This configuration file presents the layers and services that compose the Smart Surveillance example. The Flink Cluster
(single node, quantity: 1) is composed of one Job Manager and one Task Manager. The Kafka Cluster (single node, quantity: 1)
consists of a Zookeeper server and a Kafka Broker. Lastly, we have gateways (4 nodes: quantity: 1 and repeat: 3) and
the data producers (two nodes, quantity: 1 and repeat: 7). Note that all services will be monitored roles: [monitoring]
during the execution of experiments if you defined a monitoring service monitoring: type: dstat.
1environment:
2 job_name: cctv-example
3 walltime: "01:30:00"
4 g5k:
5 job_type: ["deploy"]
6 env_name: "debian10-x64-big"
7 cluster: parasilo
8monitoring:
9 type: dstat
10layers:
11- name: cloud
12 services:
13 - name: Flink
14 quantity: 1
15 roles: [monitoring]
16 env:
17 FLINK_PROPERTIES: "jobmanager.heap.size: 8000m\n
18 parallelism.default: 16\n
19 taskmanager.numberOfTaskSlots: 32\n
20 taskmanager.heap.size: 7000m\n
21 env.java.opts.taskmanager: -Djava.library.path=/opt/flink/lib/"
22 - name: Kafka
23 quantity: 1
24 roles: [monitoring]
25 env:
26 KAFKA_ZOOKEEPER_CONNECTION_TIMEOUT_MS: '30000'
27 KAFKA_BATCH_SIZE: '200000'
28 KAFKA_LINGER_MS: '50'
29- name: fog
30 services:
31 - name: Mosquitto
32 quantity: 1
33 roles: [monitoring]
34 repeat: 3
35- name: edge
36 services:
37 - name: Producer
38 quantity: 1
39 roles: [monitoring]
40 repeat: 7
41- name: experiment_manager
42 services:
43 - name: Metrics_collector
44 quantity: 1
Network Configuration
The file below presents the network configuration between the cloud, fog, and
edge infrastructures. Between cloud and fog we have the following
configuration delay: 5ms, loss: 2%, rate: 1gbit, while between the edge and
fog we are emulating a 4G LTE network delay: 50ms, loss: 5%, rate: 150gbit.
1networks:
2- src: cloud
3 dst: fog
4 delay: "5ms"
5 rate: "1gbit"
6 loss: "2%"
7- src: fog
8 dst: edge
9 delay: "50ms"
10 rate: "150mbit"
11 loss: "5%"
Workflow Configuration
This configuration file presents the application workflow configuration. It will be explained in the following order prepare,
launch, and finalize.
prepare
Regarding Kafka
cloud.kafka.*.leader, we are creating two topicsin-uni-dataandout-uni-datawith32 partitions.Regarding Flink Job Manager
cloud.flink.*.job_manager, we are copying from the local machine to the remote machine the Flink Job.Regarding gateways
fog.mosquitto.*, we are copying its libraries.Regarding producers
edge.producer.*, we are copying the producer java application and its libraries.Regarding metrics collector
experiment_manager.metrics_collector.*, we are copying its libraries.
launch
Regarding Flink Job Manager
cloud.flink.*.job_manager, we are copying it to the container and submitting the Flink Job.Regarding gateways
fog.mosquitto.*, we are starting the java application.Regarding producers
edge.producer.*, we are starting 40 java processes per node. We used thedepends_onattribute to interconnect the 320 producers with the 4 gateways in round robingrouping: "round_robin". This configuration may be seen in theshellcommand, where we used the prefix mosquittoprefix: "mosquitto"to access the URL of gateways{{ mosquitto.url }}.Regarding metrics collector
experiment_manager.metrics_collector.*, we are starting the java application to collect some metrics.
finalize
Regarding Kafka
cloud.kafka.*.leader, we are stopping and removing Kafka and Zookeeper docker containers.Regarding Flink Job Manager
cloud.flink.*.job_manager, we are stopping and removing the Task Manager container.Regarding gateways
fog.mosquitto.*, we are collecting the metrics of all4 gateways, such as their latency and throughput.Regarding producers
edge.producer.*, we are collecting the metrics of all320 producers, such as their throughput.Regarding metrics collector
experiment_manager.metrics_collector.*, we are collecting the end-to-end processing latency.
1# KAFKA
2- hosts: cloud.kafka.*.leader
3 depends_on:
4 service_selector: "cloud.kafka.*.zookeeper"
5 grouping: "round_robin"
6 prefix: "zookeeper"
7 prepare:
8 - debug:
9 msg: "Creating my Kafka topics"
10 - shell: "sudo docker exec leader /usr/bin/kafka-topics --create --partitions 32 --replication-factor 1 --if-not-exists --zookeeper {{ zookeeper.url }} --topic in-uni-data"
11 - shell: "sudo docker exec leader /usr/bin/kafka-topics --create --partitions 32 --replication-factor 1 --if-not-exists --zookeeper {{ zookeeper.url }} --topic out-uni-data"
12 finalize:
13 - debug:
14 msg: "Stopping Kafka and Zookeeper"
15 - shell: "sudo docker container stop leader && sudo docker container rm leader"
16 - shell: "sudo docker container stop zookeeper && sudo docker container rm zookeeper"
17# FLINK
18- hosts: cloud.flink.*.job_manager
19 depends_on:
20 service_selector: "cloud.kafka.*.leader"
21 grouping: "round_robin"
22 prefix: "kafka"
23 prepare:
24 - debug:
25 msg: "Copying my Flink job dependencies"
26 - copy:
27 src: "{{ working_dir }}/university-people-count-flink-partial-on-cloud-0.0.1-SNAPSHOT.jar"
28 dest: "/opt/university-people-count-flink-partial-on-cloud-0.0.1-SNAPSHOT.jar"
29 - copy:
30 src: "{{ working_dir }}/libs/"
31 dest: "/opt/lib/"
32 - copy:
33 src: "{{ working_dir }}/libs-opencv/"
34 dest: "/opt/lib/"
35 launch:
36 - debug:
37 msg: "Starting my Flink job"
38 - shell: "sudo docker cp /opt/university-people-count-flink-partial-on-cloud-0.0.1-SNAPSHOT.jar {{ self_container }}:/opt/ &&
39 sudo docker cp /opt/lib/ task_manager:/opt/flink/"
40 - shell: "sudo docker exec {{ self_container }} flink run -d -q /opt/university-people-count-flink-partial-on-cloud-0.0.1-SNAPSHOT.jar
41 32 {{ kafka.url }} in-uni-data out-uni-data {{ kafka.url }} 20"
42 finalize:
43 - debug:
44 msg: "Stopping Flink"
45 - shell: "sudo docker container stop task_manager && sudo docker container rm task_manager"
46# GATEWAYS
47- hosts: fog.mosquitto.*
48 depends_on:
49 - service_selector: "fog.mosquitto.*"
50 grouping: "address_match"
51 prefix: "mosquitto"
52 - service_selector: "cloud.kafka.*.leader"
53 grouping: "round_robin"
54 prefix: "kafka"
55 prepare:
56 - debug:
57 msg: "Copying my active gateways libs (Mosquitto + Edgent) from: {{ working_dir }}"
58 - copy:
59 src: "{{ working_dir }}/libs/"
60 dest: "/opt/lib/"
61 - copy:
62 src: "{{ working_dir }}/libs-opencv/"
63 dest: "/opt/lib/"
64 launch:
65 - debug:
66 msg: "Starting my active gateways (Mosquitto + Edgent)"
67 - shell: "java -Djava.library.path=/opt/lib/ -cp /opt/lib/*:/opt/lib university_people_count.university_people_count_fog_to_cloud.UniversityPeopleCountActiveMosquittoToKafka
68 tcp://{{ mosquitto.url }} in-uni-data 0 tcp://{{ kafka.url }} in-uni-data 0 10 100 /tmp/mosquitto /opt/metrics 2>&1 | tee -a /opt/cctv-ag.log"
69 async: 260
70 poll: 0
71 finalize:
72 - debug:
73 msg: "Backup gateways metrics to {{ working_dir }} + /experiment-results/gateways/"
74 - fetch:
75 src: "/opt/metrics/latency"
76 dest: "{{ working_dir }}/experiment-results/gateways/"
77 validate_checksum: no
78 - fetch:
79 src: "/opt/metrics/throughput"
80 dest: "{{ working_dir }}/experiment-results/gateways/"
81 validate_checksum: no
82# PRODUCERS
83- hosts: edge.producer.*
84 depends_on:
85 service_selector: "fog.mosquitto.*"
86 grouping: "round_robin"
87 prefix: "mosquitto"
88 prepare:
89 - debug:
90 msg: "Copying producer libs"
91 - copy:
92 src: "{{ working_dir }}/libs/"
93 dest: "/opt/lib/"
94 - copy:
95 src: "{{ working_dir }}/dataset/"
96 dest: "/opt/dataset/"
97 launch:
98 - debug:
99 msg: "Starting producers and connecting them with gateways (round robin)"
100 - shell: "java -Xms256m -Xmx1024m -cp /opt/lib/*:/opt/lib university_people_count.university_people_count_data_source.UniversityPeopleCountDataSourceToMosquitto
101 /opt/dataset/data-{{ item }} 10 {{ item }} tcp://{{ mosquitto.url }} in-uni-data /tmp/mosquitto 220 0 /opt/metrics-{{ item }}
102 2>&1 | tee -a /opt/cctv-producer-{{ item }}.log"
103 async: 220
104 poll: 0
105 loop: "{{ range(1, 41)|list }}"
106 finalize:
107 - debug:
108 msg: "Backup producers metrics"
109 - fetch:
110 src: "/opt/metrics-{{ item }}/throughput"
111 dest: "{{ working_dir }}/experiment-results/producers/"
112 validate_checksum: no
113 loop: "{{ range(1, 41)|list }}"
114# METRICS COLLECTOR
115- hosts: experiment_manager.metrics_collector.*
116 depends_on:
117 service_selector: "cloud.kafka.*.leader"
118 grouping: "round_robin"
119 prefix: "kafka"
120 prepare:
121 - debug:
122 msg: "Copying application to collect the experiment metrics"
123 - copy:
124 src: "{{ working_dir }}/libs/"
125 dest: "/opt/lib/"
126 launch:
127 - debug:
128 msg: "Starting my application to collect the experiment metrics"
129 - shell: "sleep 20 && java -cp /opt/lib/*:/opt/lib university_people_count.university_people_count_sink.UniversityPeopleCountCloudInSink {{ kafka.url }}
130 in-uni-data 0 /opt/metrics/in-sink 2>&1 | tee -a /opt/cctv-sink-input-cloud.log"
131 async: 230
132 poll: 0
133 - shell: "sleep 20 && java -cp /opt/lib/*:/opt/lib university_people_count.university_people_count_sink.UniversityPeopleCountOutSink {{ kafka.url }}
134 out-uni-data 0 /opt/metrics/out-sink 2>&1 | tee -a /opt/cctv-sink-output.log"
135 async: 230
136 poll: 0
137 finalize:
138 - debug:
139 msg: "Backup sinks metrics"
140 - fetch:
141 src: "/opt/metrics/in-sink/latency"
142 dest: "{{ working_dir }}/experiment-results/sinks/in-sink/"
143 validate_checksum: no
144 - fetch:
145 src: "/opt/metrics/out-sink/latency"
146 dest: "{{ working_dir }}/experiment-results/sinks/out-sink/"
147 validate_checksum: no
Running & Verifying Experiment Execution
Find below the commands to deploy this application and check its execution. Once deployed, you can check in the Flink WebUI
the configurations that we have defined in the layers-services.yaml and workflow.yaml configuration files, such as the
number of Task Managers, total task slots, Job Manager and Task manager heap size, job parallelism, etc.
(see Figure 2: Flink WebUI, Figure 3: Flink configurations, and Figure 4: Flink Job). Besides, you can also check the data sent to
Mosquitto in-uni-data topic and Kafka in-uni-data and out-uni-data topics. For producers and metrics collector you
can check the java processes running on it.
Running multiple experiments: in this example we are running two experiments
--repeat 1, each one with a duration of four minutes--duration 240.
# G5K frontend
$ ssh rennes.grid5000.fr
$ tmux
$ cd git/e2clab/
# G5K interactive usage
$ oarsub -p "cluster='parasilo'" -l host=1,walltime=2 -I
# As soon as the host becomes available, you can run your experiments
$ source ../venv/bin/activate
$ e2clab deploy --repeat 1 --duration 240
/home/drosendo/git/cluster-2020-artifacts/getting_started/
/home/drosendo/git/cluster-2020-artifacts/artifacts/
Verifying experiment execution.
# Discover hosts in layers_services-validate.yaml file
$ cat layers_services-validate.yaml
# Tunnel to Flink Job Manager
$ ssh -NL 8081:localhost:8081 parasilo-12.rennes.grid5000.fr
# Kafka Cluster
$ ssh parasilo-14.rennes.grid5000.fr
# Kafka input topic
$ sudo docker exec -it leader /usr/bin/kafka-console-consumer --bootstrap-server localhost:9092 --topic in-uni-data
# Kafka output topic
$ sudo docker exec -it leader /usr/bin/kafka-console-consumer --bootstrap-server localhost:9092 --topic out-uni-data
# Gateway input topic
$ ssh parasilo-25.rennes.grid5000.fr
$ sudo docker exec -it mosquitto mosquitto_sub -t "in-uni-data"
# Producer
$ ssh parasilo-3.rennes.grid5000.fr
$ ps -C java | wc -l
41
$ ps -xau | grep java
java -Xms256m -Xmx1024m -cp /opt/lib/*:/opt/lib university_people_count.university_people_count_data_source.UniversityPeopleCountDataSourceToMosquitto /opt/dataset/data-1 10 1 tcp://parasilo-25.rennes.grid5000.fr:1883 in-uni-data /tmp/mosquitto 220 0 /opt/metrics-1
...
java -Xms256m -Xmx1024m -cp /opt/lib/*:/opt/lib university_people_count.university_people_count_data_source.UniversityPeopleCountDataSourceToMosquitto /opt/dataset/data-40 10 40 tcp://parasilo-25.rennes.grid5000.fr:1883 in-uni-data /tmp/mosquitto 220 0 /opt/metrics-40
# Metrics Collector
$ ssh parasilo-9.rennes.grid5000.fr
$ ps -xau | grep java
java -cp /opt/lib/*:/opt/lib university_people_count.university_people_count_sink.UniversityPeopleCountCloudInSink parasilo-14.rennes.grid5000.fr:9092 in-uni-data 0 /opt/metrics/in-sink
java -cp /opt/lib/*:/opt/lib university_people_count.university_people_count_sink.UniversityPeopleCountOutSink parasilo-14.rennes.grid5000.fr:9092 out-uni-data 0 /opt/metrics/out-sink
In Figure 2: Flink WebUI you can check: the single Task Manager configured with 32 task slots
taskmanager.numberOfTaskSlots: 32.
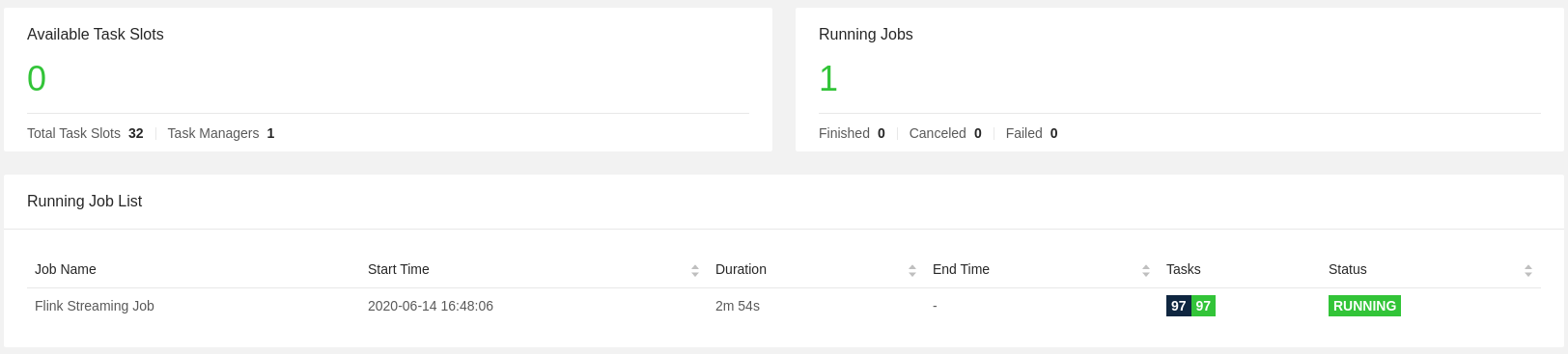
Figure 2: Flink WebUI
In Figure 3: Flink configurations you can check:
env.java.opts.taskmanager: -Djava.library.path=/opt/flink/lib/,jobmanager.heap.size: 8000m,taskmanager.heap.size: 7000m, andparallelism.default: 16.
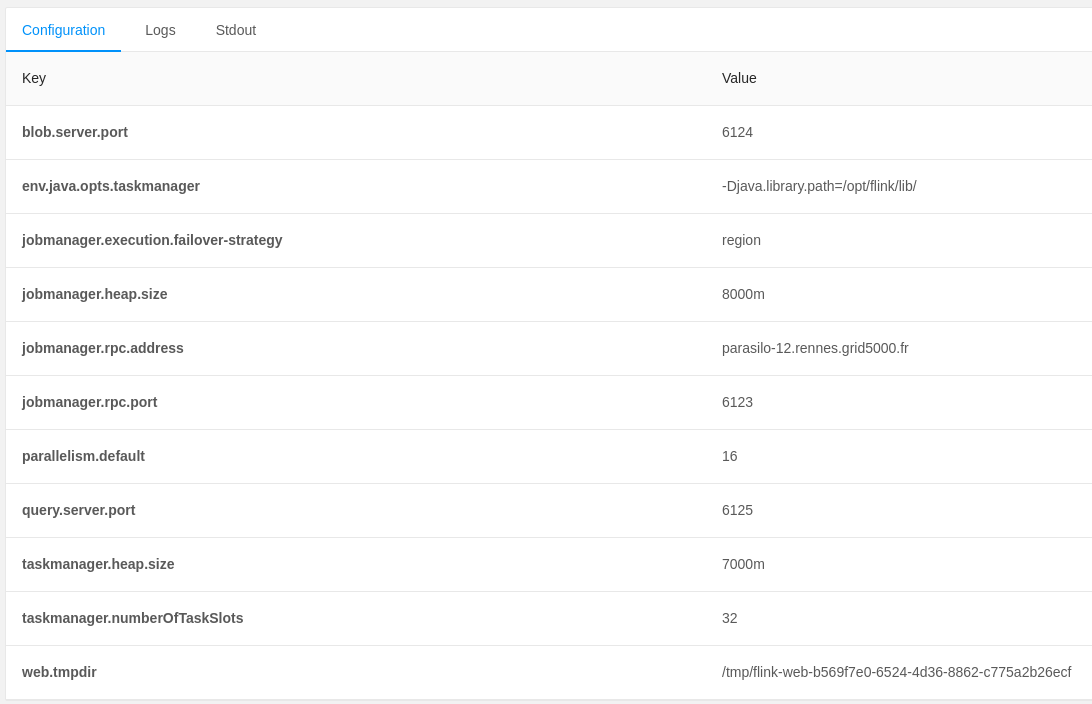
Figure 3: Flink configurations
In Figure 4: Flink Job you can check: the running job with
parallelism: 32.
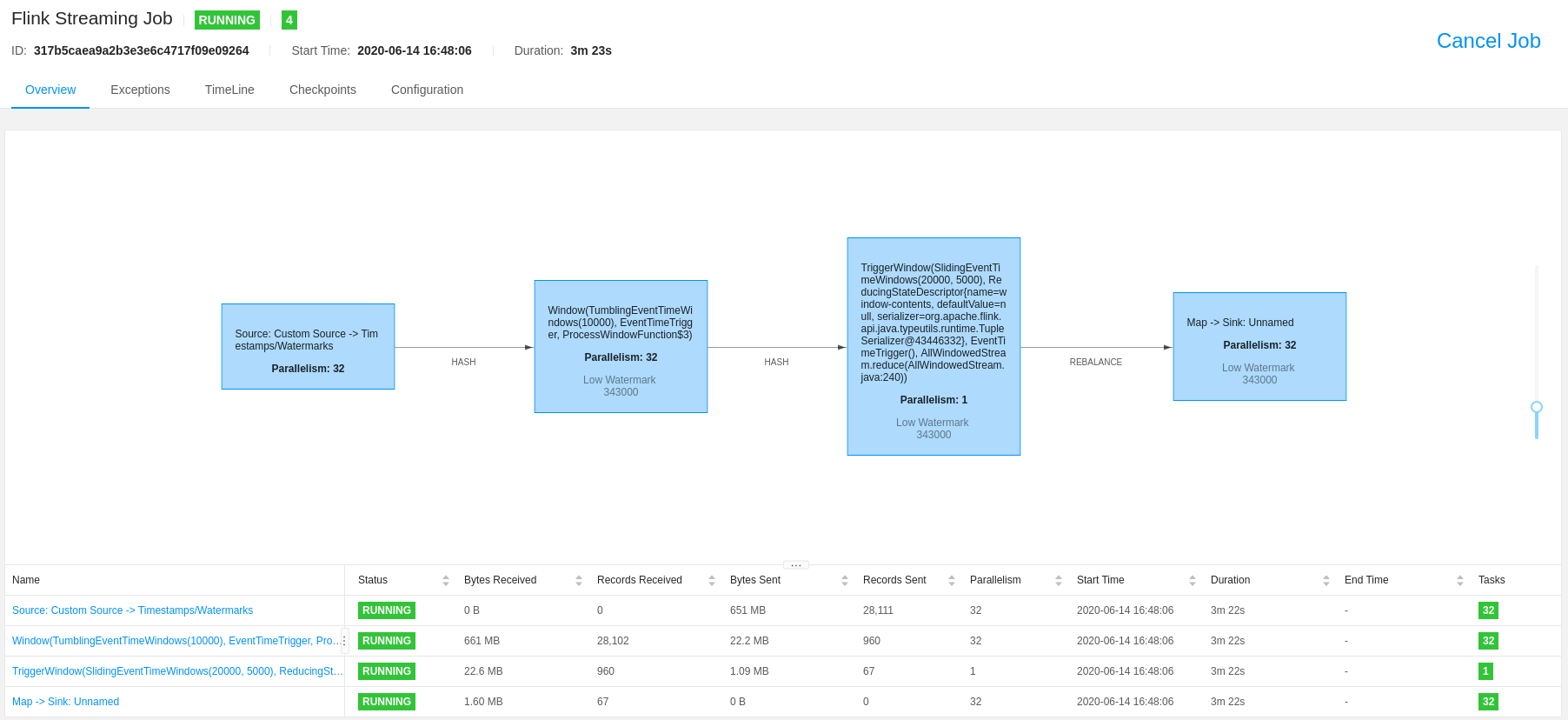
Figure 4: Flink Job
Deployment Validation & Experiment Results
Find below the files generated after the execution of each experiment. It consists of validation files
layers_services-validate.yaml, network-validate/, and workflow-validate.out, monitoring data dstat/,
and experiment-results/ (files generated by producers producers/, gateways gateways/, and metrics collector sinks/).
Note that, for each experiment a new directory is generated 20200614-155815/.
$ ls /home/drosendo/git/cluster-2020-artifacts/getting_started/20200614-155815/
dstat/ # Monitoring data for each physical machine
layers_services-validate.yaml # Mapping between layers and services with physical machines
network-validate/ # Network configuration for each physical machine
workflow-validate.out # Commands used to deploy application (prepare, launch, and finalize)
experiment-results/ # Defined in workflow file
gateways/ # latency and throughput of all gateways (4 in this example)
producers/ # throughput of all producers (320 in this example)
sinks/ # latency: fog-to-cloud and end-to-end
Note
Providing a systematic methodology to define the experimental environment and providing access to the methodology artifacts (layers_services.yaml, network.yaml, and workflow.yaml) leverages the experiment Repeatability, Replicability, and Reproducibility, see ACM Digital Library Terminology.