Optimization
The core methodology of E2Clab allows for performing reproducible experiments to understand the application performance. Such applications typically need to comply with many constraints related to resource usage (e.g., GPU, CPU, memory, storage, and bandwidth capacities), energy consumption, QoS, security, and privacy. Therefore, enabling their optimized execution across the Edge-to-Cloud Continuum is challenging. The parameter settings of the applications and the underlying infrastructure result in a complex configuration search space.
E2Clab optimization methodology
Next, we present our optimization methodology. It supports reproducible parallel optimization of application workflows on large-scale testbeds. It consists of three main phases illustrated in Figure 1: E2Clab optimization methodology.
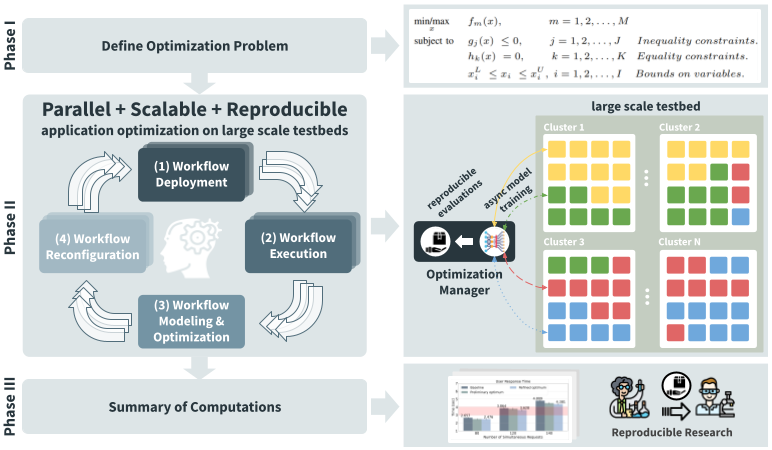
Figure 1: E2Clab optimization methodology
Phase I: Initialization
This phase, depicted at the top of Figure 1: E2Clab optimization methodology, consists in defining the optimization problem. The user must specify:
The optimization variables that compose the search space to be explored (e.g., GPUs used for processing, Fog nodes in the scenario, network bandwidth, etc.)
The objective, such as minimize end-to-end latency, maximize Fog gateway throughput, among others
The constraints, such as the upper and lower bounds of optimization variables, budget, latency, etc.
Phase II: Evaluation
This phase aims at defining the optimization method and algorithm used in the optimization cycle (presented in the middle of Figure 1: E2Clab optimization methodology) to explore the search space.
The optimization cycle consists in:
parallel deployments of the application workflow in large-scale testbeds
their simultaneous execution
asynchronous model training and optimization with data obtained from the workflow execution
reconfiguration of the application workflow with the configuration suggested by the search algorithm
This cycle continues until model convergence or after a given number of evaluations defined by the user.
Phase III: Finalization
For reproducibility purposes, this last phase illustrated at the bottom of Figure 1: E2Clab optimization methodology, provides a summary of computations. Therefore, it provides the definition of the optimization problem (optimization variables, objective, and constraints); the sample selection method; the surrogate models or search algorithms with their hyperparameters used to explore the search space of the optimization problem; and finally, the optimal application configuration found.
The optimization manager
We enhanced the E2Clab framework by implementing our optimization methodology on it. We added a new manager, named Optimization Manager, to manage the optimization cycle.
The Optimization Manager uses Ray Tune to parallelize the application optimization and explores state-of-the-art Bayesian Optimization libraries such as Ax, BayesOpt, BOHB, Dragonfly, FLAML, HEBO, Hyperopt, Nevergrad, Optuna, SigOpt, skopt, and ZOOpt. Which search algorithm to choose?

Figure 2: Ray Tune
How to set up an optimization?
To set up an optimization, users should define what we named User-defined optimization. For that, E2Clab provides a class-based API that allows users to easily set up and manage the optimization using the run() and run_objective() methods.
User-defined optimization
run()
In this method, users have to mainly:
Define the optimization method (e.g., Bayesian Optimization) and algorithm (e.g., Extra Trees Regressor), for instance: algo = SkOptSearch()
The parallelism level of the workflow deployments, for instance: algo = ConcurrencyLimiter(algo, max_concurrent=3)
Define the optimization problem, for instance: objective = tune.run(…)
run_objective()
prepare() creates an optimization directory. Each application deployment evaluation has its own directory.
launch(optimization_config=_config) deploys the application configurations (suggested by the search algorithm). It executes all the E2Clab commands for the deployment, such as layers_services, network, workflow (prepare, launch, finalize) and finalize.
finalize() saves the optimization results in the optimization directory.
Accessing the optimization variables from your workflow.yaml file
Users can use {{ optimization_config }} in their workflow.yaml file to get access
to the _config variables (the configuration suggested by the search algorithm, see
line 33 def run_objective(self, _config)). For instance, to pass the optimization
variables to a Python application, users could do as follows:
$ - shell: python my_application.py --config "{{ optimization_config }}"
Example
Below we provide an example of the User-defined optimization file created by the user.
Note
The User-defined optimization file must be in the ./e2clab/e2clab/optimizer/ directory.
1from e2clab.optimizer import Optimization
2from ray import tune
3from ray.tune.search import ConcurrencyLimiter
4from ray.tune.schedulers import AsyncHyperBandScheduler
5from ray.tune.search.skopt import SkOptSearch
6import yaml
7
8
9class UserDefinedOptimization(Optimization):
10
11 def run(self):
12 algo = SkOptSearch()
13 algo = ConcurrencyLimiter(algo, max_concurrent=3)
14 scheduler = AsyncHyperBandScheduler()
15 objective = tune.run(
16 self.run_objective,
17 metric="user_response_time",
18 mode="min",
19 name="my_application",
20 search_alg=algo,
21 scheduler=scheduler,
22 num_samples=9,
23 config={
24 'num_workers': tune.randint(1, 10),
25 'cores_per_worker': tune.randint(20, 50),
26 'memory_per_worker': tune.randint(1, 3)
27 },
28 fail_fast=True
29 )
30
31 print("Hyperparameters found: ", objective.best_config)
32
33 def run_objective(self, _config):
34 # '_config' is the configuration suggested by the algorithm
35 # create an optimization directory using "self.prepare()"
36 self.prepare()
37 # update the parameters of your application configuration files
38 # using 'self.optimization_dir' you can locate your files
39 # update your files with the values in '_config' (suggested by the algorithm)
40 with open(f'{self.optimization_dir}/layers_services.yaml') as f:
41 config_yaml = yaml.load(f, Loader=yaml.FullLoader)
42 for layer in config_yaml["layers"]:
43 for service in layer["services"]:
44 if service["name"] in ["myapplication"]:
45 service["quantity"] = _config["num_workers"]
46 with open(f'{self.optimization_dir}/layers_services.yaml', 'w') as f:
47 yaml.dump(config_yaml, f)
48
49 # deploy the configurations using 'self.launch()'
50 self.launch(optimization_config=_config)
51
52 # after the application ends the execution, save the optimization results
53 # using 'self.finalize()'
54 self.finalize()
55 # get the metric value generated by your application after its execution
56 # this metric is what you want to optimize
57 # for instance, the 'user_response_time' is saved in the 'self.experiment_dir'
58 user_response_time = 0
59 with open(f'{self.experiment_dir}/results/results.txt') as file:
60 for line in file:
61 user_response_time = float(line.rstrip().split(',')[1])
62
63 # report the metric value to Ray Tune, so it can suggest a new configuration
64 # to explore. Do it as follows:
65 tune.report(user_response_time=user_response_time)
E2Clab CLI
Use the following command to execute the optimization.
$ e2clab optimize /path/to/scenario/ /path/to/artifacts/
The command usage is as follows:
Usage: e2clab optimize [OPTIONS] SCENARIO_DIR ARTIFACTS_DIR
Optimize application workflow.
Options:
--duration INTEGER Duration of each experiment in seconds.
--repeat INTEGER Number of times to repeat the experiment.
--help Show this message and exit.
Try some examples
We provide a toy example here.